Reading Group Session #1
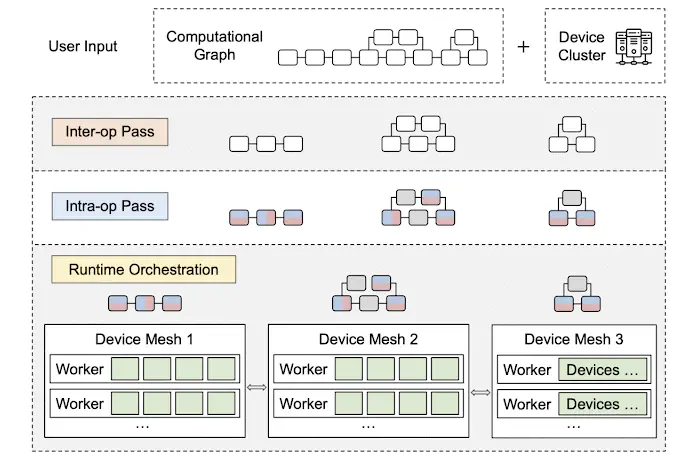 Image credit: Google AI
Image credit: Google AIAbstract
We discuss two recent works focused on distributed DL training. vPipe is a virtualized memory manager for pipeline parallel training. Alpa is a runtime capable of autoparallelization of large deep networks.
Papers
Papers covered will be:
- vPipe: A Virtualized Acceleration System for Achieving Efficient and Scalable Pipeline Parallel DNN Training, TPDS'21
- Alpa: Automating Inter-and Intra-Operator Parallelism for Distributed Deep Learning, OSDI'22
Discussion Notes
In these discussion notes we attempt to summarize points made during the discussion on possible future directions.
vPipe
Online partitioning
vPipes justification for the need for an online repartitioning algorithm is Neural Architecture Search (NAS). Very few systems are using online partitioning nowadays. The question is, is there a need for them? What are other motivating reasons for online partitioning?
- To deal with failures
- To support elasticity
- NAS
- Dynamic networks
In short, any source of dynamism in the training is justifiable. What are other sources of dynamism in training?
PCIe Usage
In vPipe PCIe is shared by swapping and inter-host activation communication. The algorithm which decides the swap-recompute plan attempts to fill all the PCIe bandwidth but ignores activation communication traffic. Is this optimal? Won’t this cause stalls by oversubscribing the PCIe bus? Still, vPipe prioritizes inter-host activation communication.
Alpa
Device Meshes
Alpa maps computations to a 2D mesh of devices. This seems to be due to the fact that there are 2 layers in the device hierarchy, intra-host and inter-host, where communication intra-host is faster than inter-host. If there were a third level in this hierarchy, perhaps a 3D mesh of devices would make sense.
Both papers
We noticed that both papers attempt to solve the NP-Complete task of parallelizing a computational graph across several devices for optimal performance. This task is too difficult to solve directly. To tackle this, both papers use a decomposition approach, instead solving two subproblems optimally:
- Alpa first uses inter-op parallelism, then intra-op parallelism on each stage.
- vPipe first uses inter-op parallelism, then computes a swap/recompute plan for each stage.
Why can’t it be solved directly? Is it simply too large a search problem? Are we losing something by not solving the original problem optimally?
Heterogeneous Clusters
Heterogeneous clusters are a reality in several organizations which over time accumulate several generations of accelerators. Furthermore, CPUs are a largely unused resource that is available. Both papers, and other systems, generally target homogeneous clusters only. We believe there is space for novel systems targeting Heterogeneous clusters, though the problem of partitioning and parallelizing becomes more difficult.