Reading Group Session #2
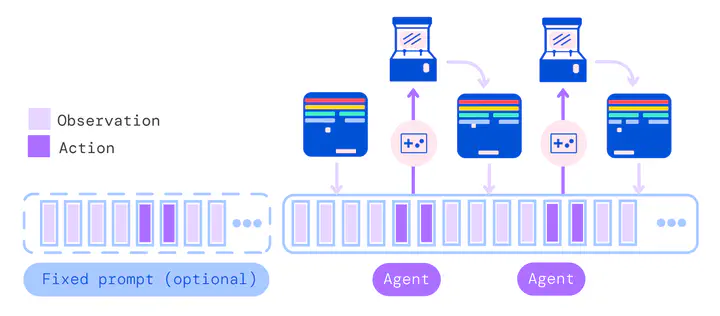 Image credit: DeepMind
Image credit: DeepMindAbstract
We discuss Gato, a new generalist model and its implications for systems designers.
Papers
A Generalist Agent, arXiv'22
Paper Abstract: Inspired by progress in large-scale language modeling, we apply a similar approach towards building a single generalist agent beyond the realm of text outputs. The agent, which we refer to as Gato, works as a multi-modal, multi-task, multi-embodiment generalist policy. The same network with the same weights can play Atari, caption images, chat, stack blocks with a real robot arm and much more, deciding based on its context whether to output text, joint torques, button presses, or other tokens. In this report we describe the model and the data, and document the current capabilities of Gato.
Discussion Notes
Gato is a new take on how to achieve multi-task agents based on autoregressive modeling of sequence data.
This paper was perhaps a bit out of scope for a SysML group, but we came up with a few future directions from the reading.
Input pipeline
The input pipeline in Gato is far more complex than a conventional Supervised Learning input pipeline
The inputs come from a large number of datasets (604, one per task) all which have large corpora. Are available sampling mechanisms able to scale to these dimensions?
Furthermore, on each iteration it requires tokenization, linearization and embedding of multi-modal inputs such that a batch containing a mix of tasks is formed. While images are embedded using a ResNet block, text, actions and observations are embedded through a learned embedding. Are existing libraries such as tf.data capable of such complex input pipelines? Can they maintain good throughput with these unbalanced tasks?
Democratizing Fine-Tuning
A common pattern nowadays seems to be that large research groups will pre-train extremely large general models (language models) and other groups will then fine-tune them to achieve good performance on a specific task (fine-tuning). How is the workload of fine-tuning different from pre-training? Would it be possible to democratize fine-tuning such that it can be done on a laptop?
Attention, Memory and Context Windows
To maintain a memory of the recent past, Gato uses a sliding window of recent observations and actions. To achieve the long-term planning needed for general RL, an infinitely sized window would be needed. However, growing the window size in current Transformer implementations would grow memory and compute requirements too. Are Transformers the correct approach to RL? Could transformers be augmented with a long-term memory component? Or could their training systems be fundamentally altered such that they can handle larger windows without growing memory requirements?